
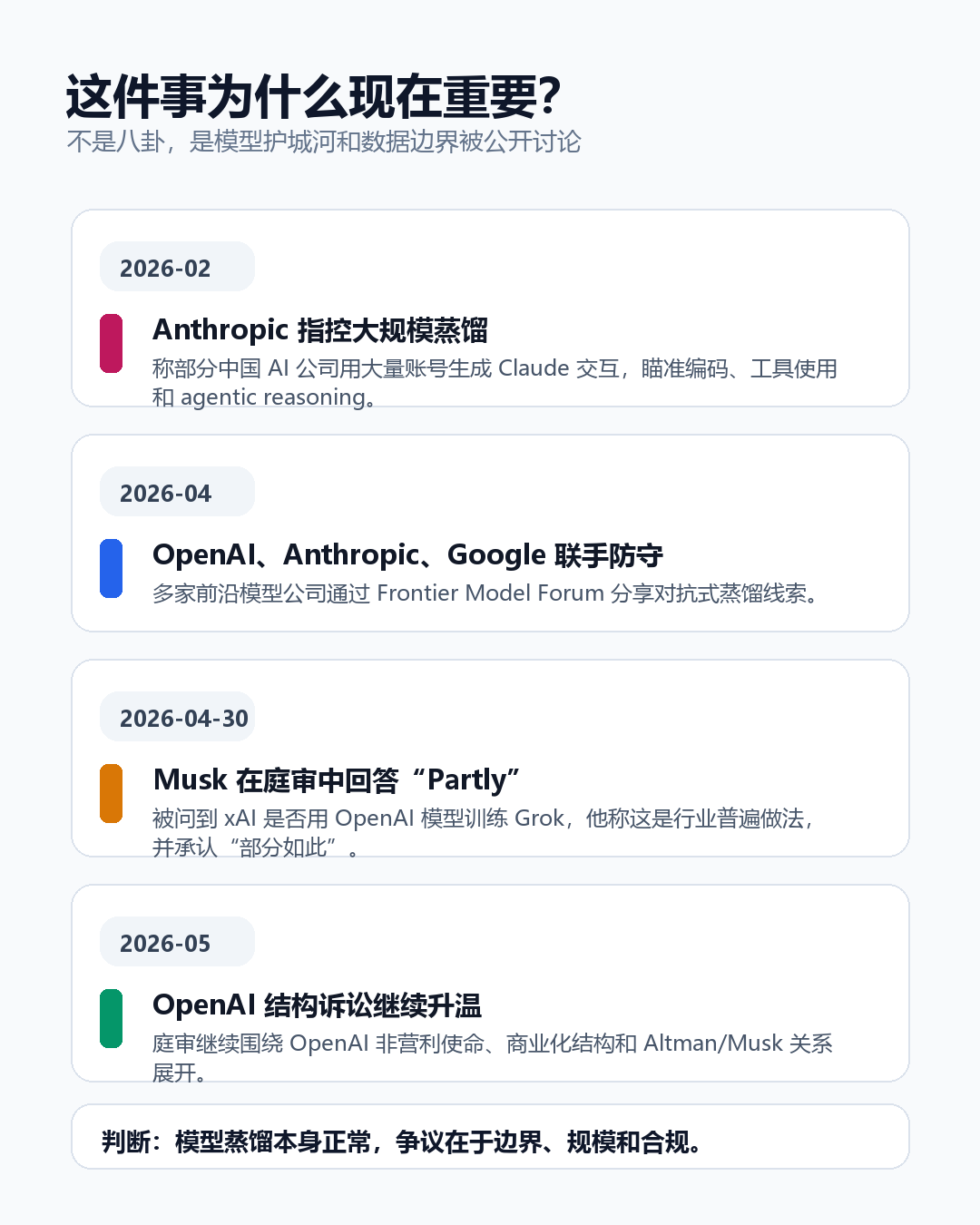
这次不是网友脑补,也不是中文科技号二手转述。
在美国加州联邦法院的 OpenAI 诉讼庭审中,Elon Musk 被问到:xAI 是否用过 OpenAI 的模型来训练 Grok?根据 TechCrunch、WIRED 等英文媒体在庭审现场的报道,Musk 先说这是 AI 公司里的普遍做法;律师继续追问是否等于“是”,他回答:Partly,也就是“部分如此”。
这句话很短,但信息量挺大。因为 OpenAI、Anthropic、Google 最近一直在防的,正是别人通过大量调用自家模型,把能力“蒸馏”进另一个模型里。
1. 先把瓜说清楚:这不是“Grok 偷了 ChatGPT”这么简单
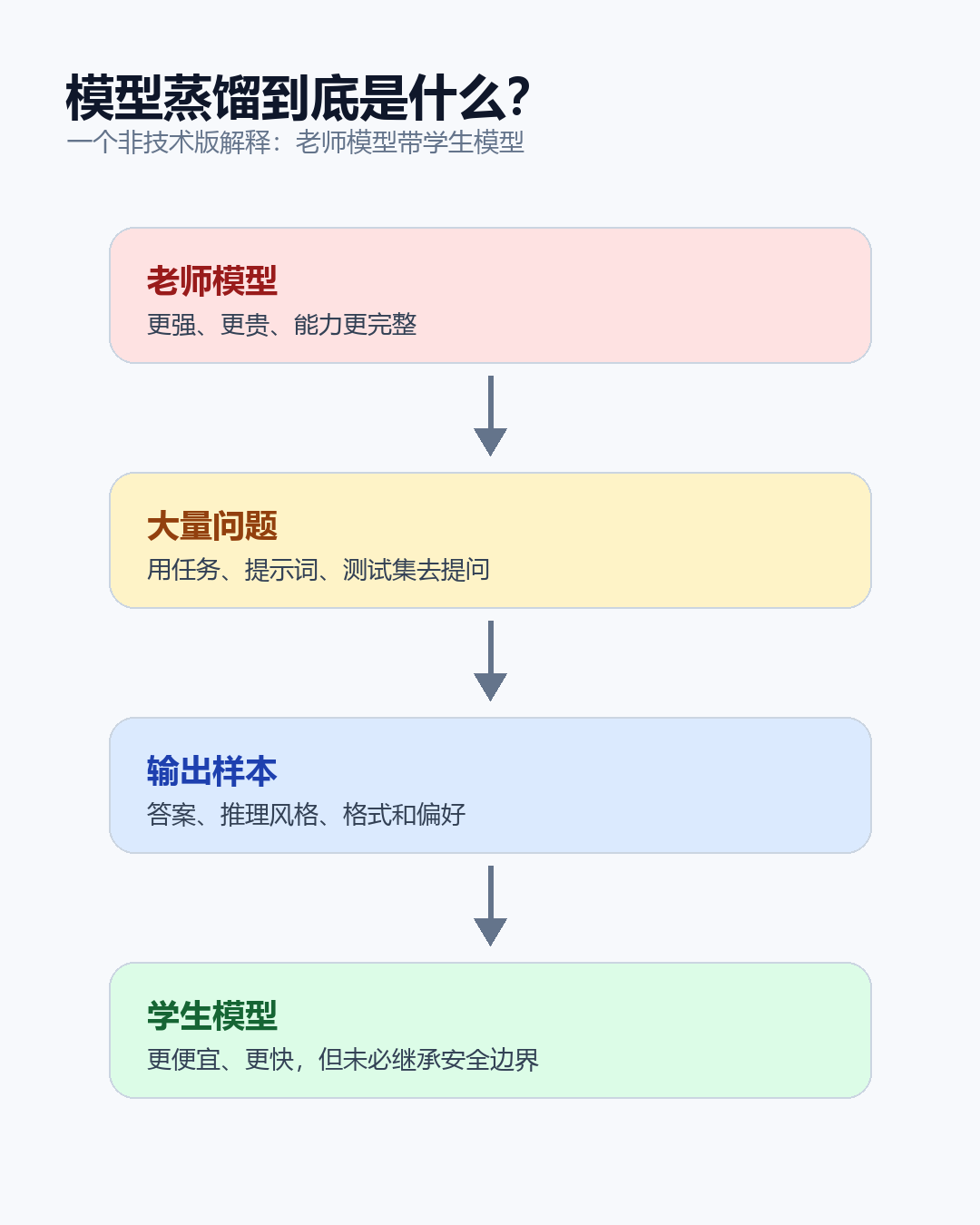
庭审里的关键词叫 distillation,中文通常翻译成“模型蒸馏”或“知识蒸馏”。简单说,就是让一个“学生模型”去学习一个更强“老师模型”的输出规律。
这项技术本身并不邪恶。很多 AI 公司都会用它来把大模型压缩成小模型,让模型更便宜、更快、更适合部署到手机、电脑、企业内网里。
真正有争议的是另一种情况:如果你不是用自己的老师模型,而是大量调用竞争对手的模型,让它回答成千上万、甚至上千万个问题,再用这些输出训练自己的模型,那就从正常技术优化,变成了商业边界和服务条款问题。
用普通话说:自己老师教自己学生,没问题;天天跑去隔壁补习班偷录老师讲课,再开一家低价补习班,就很难说只是“学习先进经验”了。
2. 为什么这件事现在爆了?
过去一年,模型能力差距越来越难保持。训练一个前沿模型需要巨额算力、数据、研究团队和调参经验。但如果后来的公司能通过蒸馏,把领先模型的推理风格、代码能力、工具使用能力复制一部分过来,追赶成本就会大幅下降。
这也是为什么 OpenAI、Anthropic、Google 会开始通过 Frontier Model Forum 分享信息,试图识别和防范所谓 adversarial distillation,也就是对抗式蒸馏。
所以 Musk 那句“Partly”之所以值得写,不是因为它能直接证明 xAI 违法,而是因为它让一个行业潜规则突然变成了公开讨论:当所有模型都在互相 benchmark、互相学习、互相防守,AI 公司的护城河到底还剩什么?
3. 模型蒸馏到底是什么?
你可以把模型蒸馏想象成:一个经验很足的老师,带一个更便宜、更轻量的学生。
老师模型做题时,不只告诉你标准答案,还会暴露很多细微判断:这个答案为什么更可能,对另一个答案为什么不太确定,遇到复杂问题时先拆哪一步。
学生模型看得多了,就会学到老师的做题习惯。放到大语言模型时代,问题复杂了。因为“老师”可能不是你自己的模型,而是别人家的商业模型;“作业本”可能来自 API 输出;“学生”可能最后变成一个公开售卖的竞争产品。
4. 普通人为什么要关心?
第一,它会影响 AI 工具价格。如果模型能力更容易被蒸馏,头部模型的高价护城河会被冲击。长期看,普通人可能用到更便宜、更快的模型。
第二,它会影响 AI 产品质量。蒸馏不是魔法。学生模型学到的是老师的输出习惯,不一定学到完整能力和安全边界。它可能在常见问题上很像老师,但一到复杂、罕见、带风险的场景,就露馅。
第三,它会影响你的数据安全。有些便宜 API、中转站、第三方镜像服务,可能会收集你的输入和输出,再转手用于训练或出售。不要为了省几块钱,把客户资料、代码、合同、个人隐私丢进来路不明的 AI 服务。
第四,它会影响内容创作者。以后互联网上高质量内容、专业问答、行业资料,都会更容易成为 AI 训练和蒸馏的燃料。创作者要更在意自己的内容分发渠道、授权方式和可替代性。
5. 哪些可信,哪些要打折?
可信的是:模型蒸馏确实是 AI 行业常见技术,学术界和工业界都长期使用。
可信的是:用竞争对手模型输出训练新模型,确实会威胁头部公司的商业优势,所以 OpenAI、Anthropic、Google 才会联手防守。
需要谨慎的是:Musk 说“大家都这么做”,这句话本身也是一种庭审语境下的防御姿态。它不能自动证明所有公司都以同样方式、同样规模、同样合规程度做了这件事。
也需要谨慎的是:OpenAI 和 Anthropic 一边反对别人蒸馏自己的模型,一边自身也长期面对版权训练数据争议。所以这不是“谁纯洁谁邪恶”的故事,更像是 AI 行业从野蛮生长走向规则谈判的阶段。
6. 普通人现在可以怎么做?
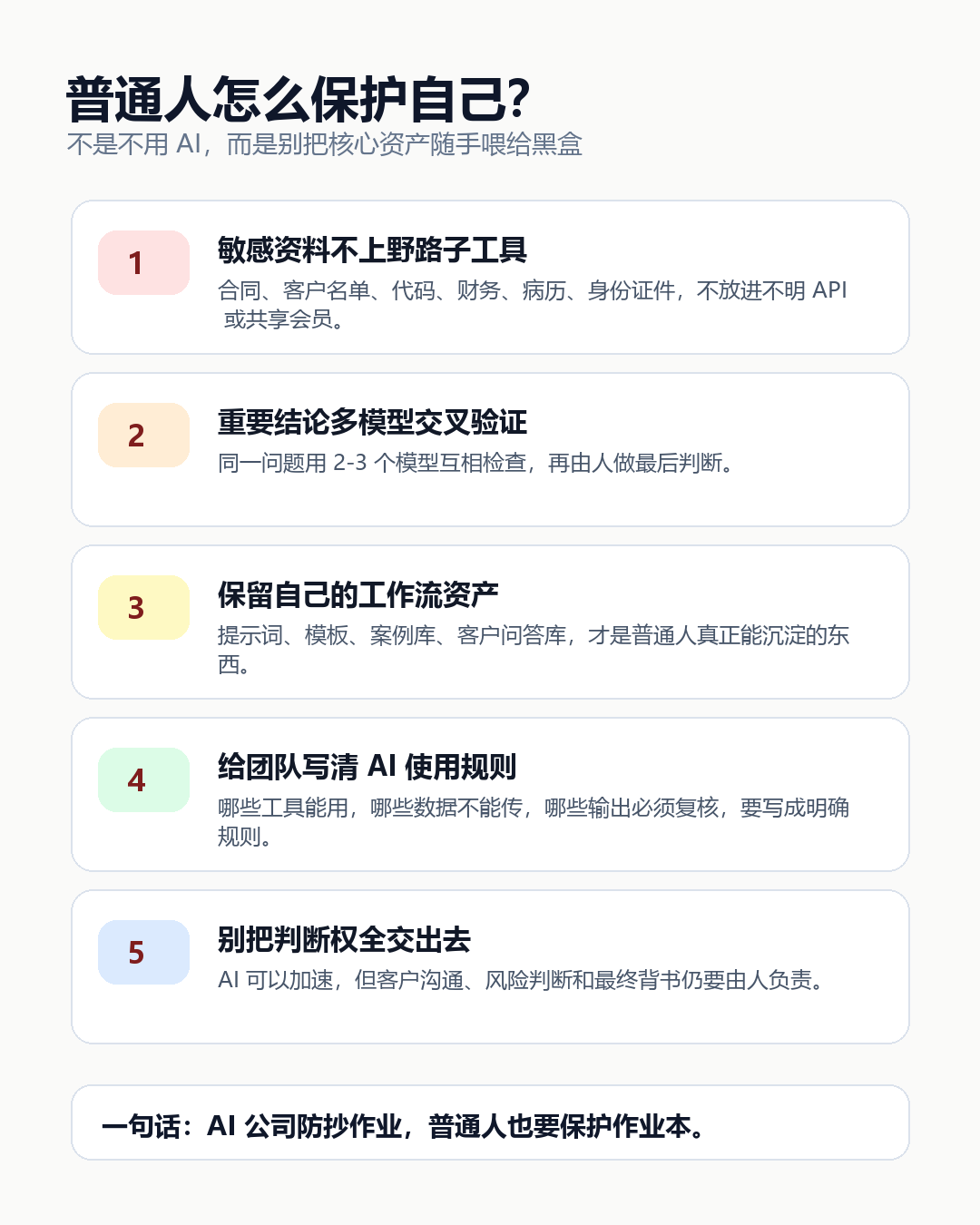
第一,别把敏感资料丢进不明 AI 工具。尤其是低价 API、中转站、破解版、所谓“共享会员”。便宜不是问题,问题是你不知道数据去了哪里。
第二,做内容和业务时,不要只依赖一个模型。同一个问题,可以用 ChatGPT、Claude、Gemini、DeepSeek 等多个模型交叉验证。真正有价值的是你自己的判断框架,而不是某个模型的一次回答。
第三,学习“可迁移的 AI 用法”。不要只记某个工具按钮在哪里,而要学会拆任务、写需求、做验收、设边界。模型会变,工作流会留下。
第四,企业和小团队要把 AI 使用规则写清楚。哪些数据不能上传?哪些工具可以用?哪些输出必须人工复核?一个小工作室、一家本地门店、一个内容团队,也需要基本边界。
我的判断
这次庭审最有价值的地方,不是让我们站队 Musk 或 Altman。
更重要的是,它提醒我们:AI 公司的竞争正在从“谁模型更强”,进入“谁的数据边界更清楚、谁的生态更可信、谁能防住别人复制能力”的阶段。
对普通人来说,短期好处是工具会越来越便宜、越来越多;长期风险是低价工具背后的数据流向会更复杂。
所以别只问“哪个 AI 最强”。更该问三个问题:这个工具的数据怎么处理?输出能不能复核?我有没有把自己的核心能力外包给一个随时可能变价、变规则、变模型的黑盒?
AI 行业已经开始互相防抄作业了。普通人也该学会保护自己的作业本。